It was in June 1994 that Hewlett-Packard announced their joint research-and development project aimed at providing advanced technologies for end-of- the-millennium workstation, server and enterprise-computing products and October 1997 that they revealed the first details of their 64-bit computing architecture. At that time the first member of Intel’s new family of 64-bit processors – codenamed Merced, after a Californian river – was slated for production in 1999, using Intel’s 0.18-micron technology. In the event the Merced development programme slipped badly and was estimated at still nearly a year from completion when Intel announced the selection of the brand name Itanium at the October 1999 Intel Developer Forum.
A major benefit of a 64-bit computer architecture is the amount of memory that can be addressed. In the mid-1980s, the 4GB addressable memory of 32-bit platforms was more than sufficient. However, by the end of the millennium large databases exceeded this limit. The time taken to access storage devices and load data into virtual memory has a significant impact on performance. 64-bit platforms are capable of addressing an enormous 16 TB of memory – 4 billion times more than 32-bit platforms are capable of handling. In real terms this means that whilst a 32-bit platform can handle a database large enough to contain the name of every inhabitant of the USA since 1977, a 64-bit one is sufficiently powerful to store the name of every person who’s lived since the beginning of time! However, notwithstanding the impact that its increased memory addressing will have, it is its Explicitly Parallel Instruction Computing (EPIC) technology – the foundation for a new 64-bit Instruction Set Architecture (ISA) – that represents Itanium’s biggest technological advance.
EPIC, incorporating an innovative combination of speculation, prediction and explicit parallelism, advances the state-of-art in processor technologies, specifically addressing the performance limitations found in RISC and CISC technologies. Whilst both of these architectures already use various internal techniques to try to process more than one instruction at once where possible, the degree of parallelism in the code is only determined at run-time by parts of the processor that attempt to analyse and re-order instructions on the fly. This approach takes time and wastes die space that could be devoted to executing, rather than organising instructions. EPIC breaks through the sequential nature of conventional processor architectures by allowing software to communicate explicitly to the processor when operations can be performed in parallel.
The result is that the processor can simply grab as large a chunk of instructions as possible and execute them simultaneously, with minimal pre-processing. Increased performance is realised by reducing the number of branches and branch mis-predicts, and reducing the effects of memory-to-processor latency. The IA-64 Instruction Set Architecture – published in May 1999 – applies EPIC technology to deliver massive resources with inherent scaleability not possible with previous processor architectures. For example, systems can be designed to slot in new execution units whenever an upgrade is required, similar to plugging in more memory modules on existing systems. According to Intel the IA-64 ISA represents the most significant advancement in microprocessor architecture since the introduction of its 386 chip in 1985.
IA-64 processors will have massive computing resources including 128 integer registers, 128 floating-point registers, and 64 predicate registers along with a number of special-purpose registers. Instructions will be bundled in groups for parallel execution by the various functional units. The instruction set has been optimised to address the needs of cryptography, video encoding and other functions that will be increasingly needed by the next generation of servers and workstations. Support for Intel’sMMX technology and Internet Streaming SIMD Extensions is maintained and extended in IA-64 processors.
Whilst IA-64 is emphatically not a 64-bit version of Intel’s 32-bit x86 architecture nor an adaption of HP’s 64-bit PA-RISC architecture, it does provide investment protection for today’s existing applications and software infrastructure by maintaining compatibility with the former in processor hardware and with the latter through software translation. However, one implication of ISA is the extent to which compilers will be expected to optimise instruction streams – and a consequence of this is that older software will not run at optimal speed unless it’s recompiled. IA-64’s handling of 32-bit software has drawn criticism from AMD whose own proposals for providing support for 64-bit code and memory addressing, codenamed Sledgehammer, imposes no such penalties on older software.
The following diagrams illustrate the greater burden placed on compiler optimisation for two of IA-64’s innovative features:
- Predication, which replaces branch prediction by allowing the processor to execute all possible branch paths in parallel, and
- Speculative loading, which allows IA-64 processors to fetch data before the program needs it, even beyond a branch that hasn’t executed
Predication is central to IA-64’s branch elimination and parallel instruction scheduling. Normally, a compiler turns a source-code branch statement (such as IF-THEN-ELSE) into alternate blocks of machine code arranged in a sequential stream. Depending on the outcome of the branch, the CPU will execute one of those basic blocks by jumping over the others. Modern CPUs try to predict the outcome and speculatively execute the target block, paying a heavy penalty in lost cycles if they mispredict. The basic blocks are small, often two or three instructions, and branches occur about every six instructions. The sequential, choppy nature of this code makes parallel execution difficult.
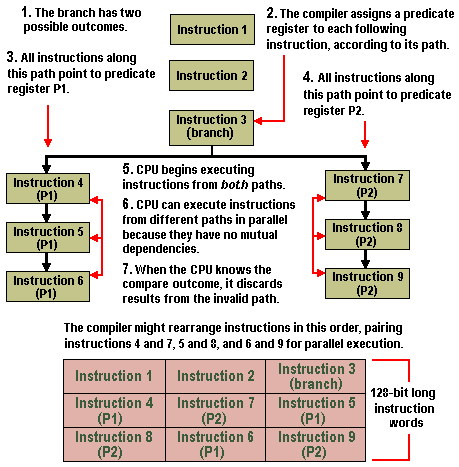
When an IA-64 compiler finds a branch statement in the source code, it analyses the branch to see if it’s a candidate for predication, marking all the instructions that represent each path of the branch with a unique identifier called a predicate for suitable instances. After tagging the instructions with predicates, the compiler determines which instructions the CPU can execute in parallel – for example, by pairing instructions from different branch outcomes because they represent independent paths through the program.
The compiler then assembles the machine-code instructions into 128-bit bundles of three instructions each. The bundle’s template field not only identifies which instructions in the bundle can execute independently but also which instructions in the following bundles are independent. So if the compiler finds 16 instructions that have no mutual dependencies, it could package them into six different bundles (three in each of the first five bundles, and one in the sixth) and flag them in the templates. At run time, the CPU scans the templates, picks out the instructions that do not have mutual dependencies, and then dispatches them in parallel to the functional units. The CPU then schedules instructions that are dependent according to their requirements.
When the CPU finds a predicated branch, it doesn’t try to predict which way the branch will fork, and it doesn’t jump over blocks of code to speculatively execute a predicted path. Instead, the CPU begins executing the code for every possible branch outcome. In effect, there is no branch at the machine level. There is just one unbroken stream of code that the compiler has rearranged in the most parallel order.
At some point, of course, the CPU will eventually evaluate the compare operation that corresponds to the IF-THEN statement. By this time, the CPU has probably executed some instructions from both possible paths – but it hasn’t stored the results yet. It is only at this point that the CPU does this, storing the results from the correct path, and discarding the results from the invalid path.
Speculative loading seeks to separate the loading of data from the use of that data, and in so doing avoid situations where the processor has to wait for data to arrive before being able to operate on it. Like prediction, it’s a combination of compile-time and run-time optimisations.
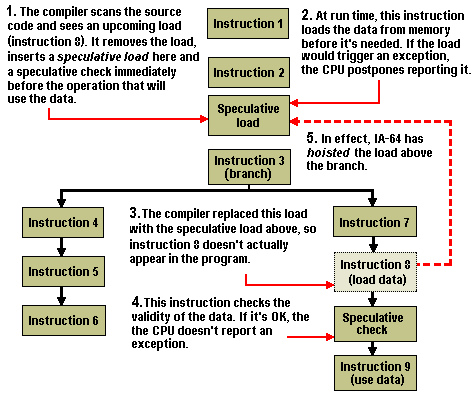
First, the compiler analyses the program code, looking for any operations that will require data from memory. Whenever possible, the compiler inserts a speculative load instruction at an earlier point in the instruction stream, well ahead of the operation that actually needs the data. It also inserts a matching speculative check instruction immediately before the operation in question. At the same time the compiler rearranges the surrounding instructions so that the CPU can despatch them in parallel.
At run time, the CPU encounters the speculative load instruction first and tries to retrieve the data from memory. Here’s where an IA-64 processor differs from a conventional processor. Sometimes the load will be invalid – it might belong to a block of code beyond a branch that has not executed yet. A traditional CPU would immediately trigger an exception – and if the program could not handle the exception, it would likely crash. An IA-64 processor, however, won’t immediately report an exception if the load is invalid. Instead, the CPU postpones the exception until it encounters the speculative check instruction that matches the speculative load. Only then does the CPU report the exception. By then, however, the CPU has resolved the branch that led to the exception in the first place. If the path to which the load belongs turns out to be invalid, then the load is also invalid, so the CPU goes ahead and reports the exception. But if the load is valid, it’s as if the exception never happened.
An important milestone was reached in August 1999 when a prototype 0.18-micron Merced CPU, running at 800MHz, was demonstrated running an early version of Microsoft’s 64-bit Windows operating system. Production Itaniums will use a three-level cache architecture, with two levels on chip and a Level 3 cache which is off-chip but connected by a full-speed bus. The first production models – currently expected in the second half of year 2000 – will come in two versions, with either 2MB or 4MB of L3 cache. Initial clock frequencies will be 800MHz – eventually rising to well beyond 1GHz.
- Principles of CPU architecture – logic gates, MOSFETS and voltage
- Basic structure of a Pentium microprocessor
- Microprocessor Evolution
- IA-32 (Intel Architecture 32 ) – base instruction set for 32 bit processors
- Pentium P5 microarchitecture – superscalar and 64 bit data
- Pentium Pro (P6) 6th generation x86 microarchitecture
- Dual Independent Bus (DIB) – frontside and backside data bus CPU architecture
- NetBurst – Pentium 4 7th generation x86 CPU microarchitecture
- Intel Core – 8th generation CPU architecture
- Moore’s Law in IT Architecture
- Architecture Manufacturing Process
- Copper Interconnect Architecture
- TeraHertz Technology
- Software Compatibility
- IA-64 Architecture
- Illustrated guide to high-k dielectrics and metal gate electrodes
this article needs to credit the DEC Alpha architecture as the original design reference for the IA64.